swift 集合协议
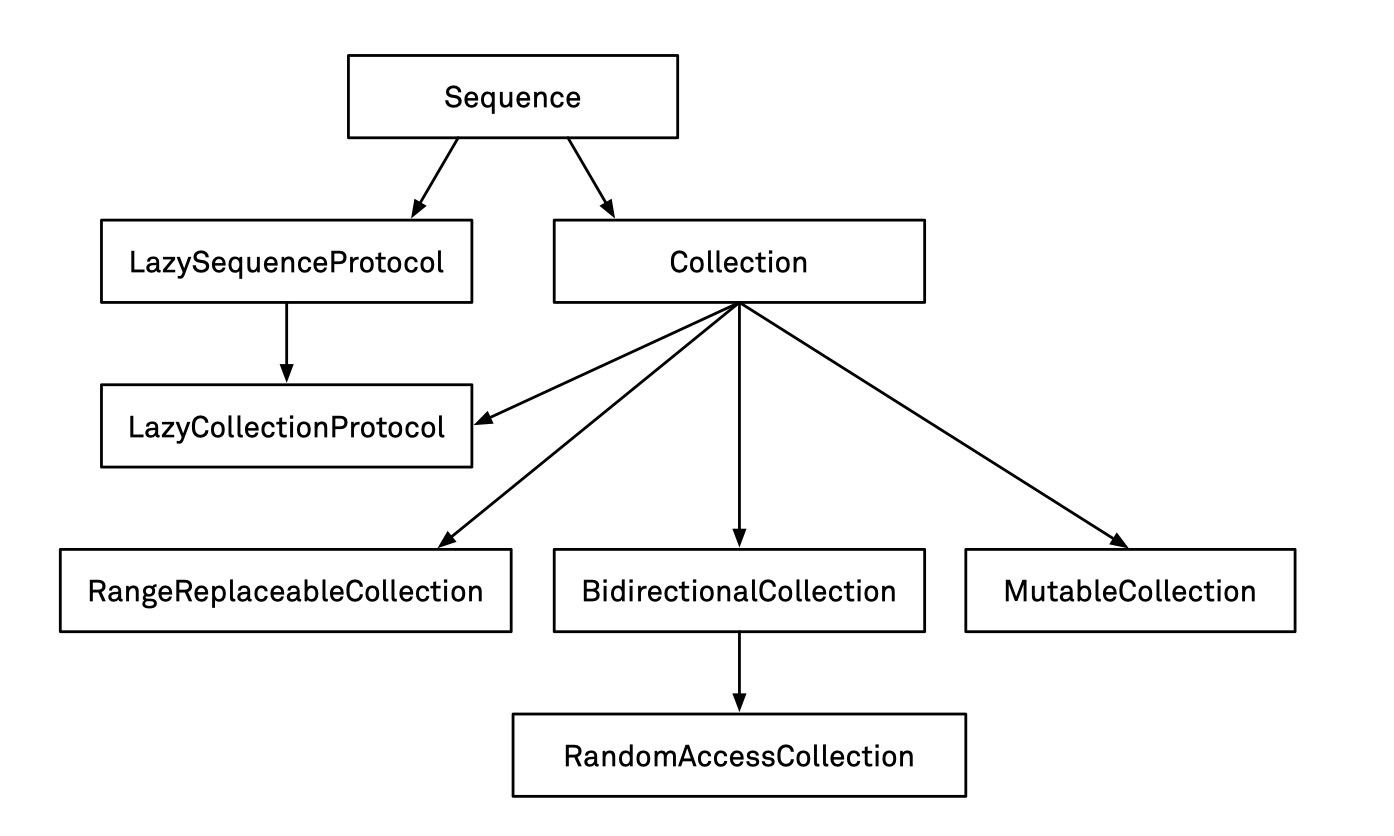
标准库中的结合协议架构
Sequence
提供了迭代的能力,允许创建一个迭代器
Collection
支持多次遍历
提供通过索引访问元素
通过 SubSequence 提供了集合切片的能力,切片自身也是一个集合
MutableCollection
提供了常数时间内,通过下标更改集合的能力
不允许向集合中添加和删除元素
RangeReplaceableCollection
提供了替换集合中一个连续区间的元素的能力。
通过扩展,衍生出 append 和 remove 等方法
Array/String 支持
Set/Dictionary 不支持
BidirectionalCollection
提供了从集合尾部想集合头部遍历的能力
RandomAccessCollection
提供了更高效的索引计算能力:计算索引的距离或者移动索引位置都是常数时间操作。
举例:Array 是随机访问的集合,但是 String 不是,因为计算两个字符之间的举例是一个线性时间的操作。
LazySequenceProtocol
定义了一个只有在开始遍历时才计算其中元素的序列 。
可以接受一个无穷序列,从中筛选元素,然后读取结果中的前几个记录。
LazyCollectionProtocol
与 LazySequenceProtocol 类似,定义一个只有在开始遍历时才计算其中元素的集合类型
Sequence Sequence 1: 有一个关联类型 Element; 2: 有一个创建迭代器的方法。
1 2 3 4 5 6 7 8 protocol Sequence { associatedtype Element where Self .Element == Self .Iterator .Element associatedtype Iterator : IteratorProtocol func makeIterator () -> Self .Iterator }
序列通过创建迭代器来提供对元素的访问。
迭代器每次产生序列中的一个值,并对序列的遍历状态管理。
迭代器遵循 IteratorProtocol。
1 2 3 4 protocol IteratorProtocol { associatedtype Element mutating func next () -> Element ? }
IteratorProtocol 的关联类型 Element 指定了迭代器产生的值得类型。where Self.Element == Self.Iterator.Element,指定迭代器及对应序列的元素相同
IteratorProtocol 协议唯一的方法 next() ,这个方法在每次被调用时返回序列的下一个值,当序列结束,返回 nil。
迭代器作用:for 循环是通过迭代器实现的
1 2 3 4 5 var iterator = someSequence.makeIterator()while let element = iterator.next() { doSomething(whit:element) }
迭代器特点:
单向结构,只能按照增加的方向前进,不能后退或重置。
通过迭代器不断迭代,可以创建一个无限的序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct PrefixIterator : IteratorProtocol { let string: String var offset: String .Index init (string : String ) { self .string = string offset = string.startIndex } mutating func next () -> Substring ? { guard offset < string.endIndex else { return nil } offset = string.index(after: offset) return string[...< offset] } } struct PrefixSequence : Sequence { let string: String func makeIterator () -> PrefixIterator { return PrefixIterator (string: string) } } for prefix in PrefixSequence (string: "abc" ) { print (prefix ) }
迭代器与值语义:
AnyIterator 是一个队别的迭代器进行封装的迭代器,封装原理是将另外的迭代器包装到一个内部的盒子对象中,而这个对象是引用类型。
基于函数的迭代器和序列
配合 AnySequence,可以在不定义新的类型的情况下,创建迭代器和序列。
单词遍历序列
序列与迭代器关系
迭代器也可以视为由他们返回的元素所组成的单次遍历序列。
Collection 集合类型(Collection)指的是那些可以被多次遍历且保持一致的序列。
除了线性遍历意外,集合中的元素也可以通过下标索引的方式访问。
集合类型不能是无限的。
每一个集合类型都有一个关联类型 SubSequence,表示集合中一段连续内容的切片。
Collection 继承了 Sequence。
实现 Collection 协议,最难的是选取合适的索引类型来表达集合类型中的位置。
实现 Collection 的类型:
swift 标准库:Array/Dictionary/Set/String/[Closed]Range/UnsafeBufferPointer
Foundation: Data/IndexSet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 protocol Collection : Sequence { associatedtype Element associatedtype Iterator = IndexingIterator <Self > override func makeIterator () -> Self .Iterator associatedtype Index : Comparable var startIndex: Self .Index { get } var endIndex: Self .Index { get } associatedtype SubSequence : Collection = Slice <Self > where Self .Element == Self .SubSequence .Element , Self .SubSequence == Self .SubSequence .SubSequence subscript (position : Self .Index ) -> Self .Element { get } subscript (bounds : Range <Self .Index >) -> Self .SubSequence { get } associatedtype Indices : Collection = DefaultIndices <Self > where Self .Indices == Self .Indices .SubSequence var indices: Self .Indices { get } var isEmpty: Bool { get } var count: Int { get } func index (_ i : Self .Index , offsetBy distance : Int ) -> Self .Index func index (_ i : Self .Index , offsetBy distance : Int , limitedBy limit : Self .Index ) -> Self .Index ? func distance (from start : Self .Index , to end : Self .Index ) -> Int func index (after i : Self .Index ) -> Self .Index func formIndex (after i : inout Self .Index ) }
实现一个队列(Queue),遵循 Collection
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct FIFOQueue <Element > { private var left: [Element ] = [] private var right: [Element ] = [] mutating func enqueue (_ newElement : Element ) { right.append(newElement) } mutating func dequeue () -> Element ? { if left.isEmpty { left = right.reversed() right.removeAll() } return left.popLast() } }
根据上面 Collection 协议的源码分析,我们最后需要实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 protocol Collection : Sequence { associatedtype Element associatedtype Index : Comparable var startIndex: Index { get } var endIndex: Index { get } func index (after i : Index ) -> Index subscript (position : Index ) -> Element { get } }
最终,实现 FIFOQueue,满足 Collection,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 extension FIFOQueue : Collection { public var startIndex: Int { return 0 } public var endIndex: Int { return left.count + right.count } public func index (after i : Int ) -> Int { precondition ( i >= startIndex && i < endIndex, "Index out of bounds" ) return i + 1 } public subscript (position : Int ) -> Element { precondition ((startIndex..< endIndex).contains(position), "Index out of bounds" ) if position < left.endIndex { return left[left.count - position - 1 ] } else { return right[position - left.count] } } }
让队列实现 ExpressibleByArrayLiteral 协议,这样可以通过字面量来创建一个队列
1 2 3 4 5 6 7 extension FIFOQueue : ExpressibleByArrayLiteral { public init (arrayLiteral elements : Element ...) { self .init (left:elements.reversed(), right:[]) } } let foo: FIFOQueue = [1 , 2 , 3 ]
Index 索引(Index),表示了集合中的位置,集合类型的索引,必须实现 Comparable 协议,即索引必须要有确定的顺序。
使用字典举例:
Dictionary,它的索引是 DictionaryIndex 类型,是一个指向字典内部存储缓冲区的不透明值。
平时使用建访问字典的 subscript(_ key: Key) 方法,是对定义在 Dictionary 中的 subscript 方法的重载。
字典的 subscript(key: Key) -> Value? ,返回的是一个可选值
集合类型的 subscript 方法,在 Collection 中,返回的是非可选值 subscript(position: Index) -> Element { get }
注意,Element 类型在字典中是一个元组:(key: Key, value: Value),所以,Dictionary 的下标访问返回的是一个键值对,也因此对 Dictionary 遍历我们得到的是键值对。
当集合发生改变时,索引可能会失效:
索引本身仍然有效,但是指向了另外的元素
索引本身无效,通过索引访问集合将造成崩溃
当前 swift 版本,通过给定索引计算新的索引,由集合本身负责。
这样可以提高性能:
String ,由于 Character 在 Swift 中的尺寸是可以改变的,因此计算 String 的索引,必须考虑 Character 的实际内容。
分割集合类型,split方法通常最合适,但是这个方法会计算整个数组。如果数组很大,但是只需要前几个元素,这样做效率低。
下面用 String(英文) 举例:
目标是,构建一个 words 集合,它能够让我们不一次性计算出所有单词,而是可以用延迟加载的方式进行迭代。
首先,从 SubString 中寻找第一个单词的范围。
使用空格作为单词的边界。
1 2 3 4 5 6 7 8 9 extension Substring { var nextWordRange: Range <Index > { let start = drop(while: { $0 == " " } ) let end = start.firstIndex(where: { $0 == " " }) ?? endIndex return start.startIndex..< end } }
第二,定义索引的类型。
通过索引下标访问某个元素,应该是一个 O(1) 的操作,因此封装 Range<Substring.Index> 来作为索引类型。
索引类型需要满足 Comparable(继承自 Equatable),此时我们采用 range 的下边界作为比较对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct WordsIndex : Comparable { fileprivate let range: Range <Substring .Index > fileprivate init (_ value : Range <Substring .Index >) { self .range = value } static func < (lhs : Words .Index , rhs : Words .Index ) -> Bool { return lhs.range.lowerBound < rhs.range.lowerBound } static func == (lhs : Words .Index , rhs : Words .Index ) -> Bool { return lhs.range == rhs.range } }
第三,构建 Words 集合类型。
在底层将 String 视为 SubString 存储;
提供两个属性: startIndex 、 endIndex;
同时,需要遵循 Collection 协议,并实现 subscript 下标方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct Words { let string: Substring let startIndex: WordsIndex public var endIndex: WordsIndex { let e = string.endIndex return WordsIndex (e..< e) } init (_ s : String ) { self .init (s[... ]) } private init (_ s : Substring ) { self .string = s self .startIndex = WordsIndex (string.nextWordRange) } } extension Words { subscript (index : WordsIndex ) -> Substring { return string[index.range] } } extension Words : Collection { public func index (after i : WordsIndex ) -> WordsIndex { guard i.range.upperBound < string.endIndex else { return endIndex } let remainder = string[i.range.upperBound... ] return WordsIndex (remainder.nextWordRange) } }
最后,使用自定义索引
1 2 3 Array (Words ("hello world test" )) Array (Words ("Hello world test" ).prefix(2 ))
补充:创建自定义集合类型时,优先考虑能否使用其本身作为自己的 SubSequence 使用
1 2 3 4 5 6 7 8 extension Words { subscript (range :Range <WordsIndex >) -> Words { let start = range.lowerBound.range.lowerBound let end = range.upperBound.range.upperBound return Words (string[start..< end]) } }
SubSequence 在 Swift5 中,SubSequence 被定义到了 Collection 协议中,是一个关联类型,表示集合中一个连续的子区间。
默认情况下,Collection 把 Slice 作为自己的 SubSequence 类型。
子序列和原始的集合类型共享内部存储。
1 2 3 4 extension Collection { associatedtype SubSequence : Collection = Slice <Self > where Element == SubSequence .Element , SubSequence == SubSequence .SubSequence }
扩展:以每 n 个元素切割集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 extension Collection { public func split (batchSize : Int ) -> [SubSequence ] { var result: [SubSequence ] = [] var batchStart = startIndex while batchStart < endIndex { let batchEnd = index(batchStart, offsetBy: batchSize, limitedBy: endIndex) ?? endIndex let batch = self [batchStart..< batchEnd] result.append(batch) batchStart = batchEnd } return result } } let letters = "abcdefg" let batches = letters.split(batchSize: 3 )
所有集合类型,都有切片操作的默认实现,并有一个下标方法:subscript(range:Range<Index>) -> Slice<Base>
Slice 非常适合作为默认的切片类型,不过当创建自定义集合时,优先考虑集合本身作为切片类型。详见 Index 。
Slice 是基于任意集合类型的一个轻量级封装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct Slice <Base : Collection >: Collection { typealias Index = Base .Index let collection: Base var startIndex: Index var endIndex: Index init (base : Base , bounds : Range <Index >) { collection = base startIndex = bounds.lowerBound endIndex = bounds.upperBound } func index (after i :Index ) -> Index { return collection.index(after: i) } subscript (position : Index ) -> Base .Element { return collection[position] } subscript (bounds : Range <Index >) -> Slice <Base > { return Slice (base: collection, bounds: bounds) } }
Collection 协议要求切片的索引和原集合的索引互换使用
集合类型和它的切片拥有相同的索引。
只要集合和它的切片在切片被创建后没有改变,切片中的某个索引位置上的元素,应当也存在于原集合中同样的索引位置上。
推荐使用索引的方式: for index in collection.indices,但不要在迭代时修改集合。
专门的集合类型 Collection 有两个限制:
无法往回移动索引;
没有提供像插入、移除或替换元素这样的改变集合内容的功能。
一个既支持向前又支持向后遍历的集合,继承 Collection
提供index(before:)方法把索引往回移动一个位置
有了向前遍历集合的能力,BidirectionalCollection 实现了一些可以高效执行的方法:suffix,removeLast,reversed
1 2 3 4 5 6 7 8 9 10 11 12 extension BidirectionalCollection { public var last: Element ? { return isEmpty ? nil : self [index(before: endIndex)] } public func reversed () -> ReversedCollection <Self > { return ReversedCollection (_ base: self ) } }
一个支持高效随机访问索引进行遍历的集合,继承 BidirectionalCollecton
可以在常数时间内跳转到任意索引,需要在常数时间内完成两个操作:第一,可以任意距离移动一个索引;第二,测量任意两个索引之间的距离。
实现index(_:offsetBy:)和distance(from:to:),或者 Index 类型满足 Strideable(比如 Int)
RandomAccessCollection 以更严格的约束重新声明了关联的 Indices 和 SubSequence 类型,这两个类型自身也必须是可以进行随机存取的。
补充:二分搜索算法,必须搭配随机存取集合。
一个支持下标赋值的集合,继承自 Collection
要求:单个元素的下标访问方法subscript现在必须提供一个 setter:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 extension FIFOQueue : MutableCollection { public var startIndex: Int { return 0 } public var endIndex: Int { return left.count + right.count } public func index (after i : Int ) -> Int { precondition ( i >= startIndex && i < endIndex, "Index out of bounds" ) return i + 1 } public subscript (position : Int ) -> Element { get { precondition ((0 ..< endIndex).contains(position), "Index out of bounds" ) if position < left.endIndex { return left[left.count - position - 1 ] } else { return right[position - left.count] } } set { precondition ((0 ..< endIndex).contains(position), "Index out of bounds" ) if position < left.endIndex { left[left.count - position - 1 ] = newValue } else { return right[position - left.count] = newValue } } } }
RangeReplaceableCollection
一个支持将任意范围的元素用别的集合中的元素进行替换的集合,继承自 Collection
此协议两个要求:
一个空的初始化方法;(在泛型函数中很有用,允许一个函数创建相同类型的空集合)
一个 replaceSubrange(_:with:)方法。(接受一个要替换的范围以及一个用来进行替换的集合)
只需要实现一个灵活的 replaceSubrange(_:with:)方法,协议扩展就可以引申一系列有用的方法:
append(_:) 和 append(contentsOf:)
remove(at:) 和 removeSubrange(_:)
insert(at:) 和 insert(contentsOf:at:)
removeAll
1 2 3 4 5 6 7 8 9 extension FIFOQueue : RangeReplaceableCollection { mutating func replaceSubrange <C :Collection > (_ subrange : Range <Int >, with newElements : C ) where C .Element == Element { right = left.reversed() + right left.removeAll() right.replaceSubrange(subrange, with: newElements) } }
1 2 3 4 5 extension MutableCollection where Self : RandomAccessCollection , Element : Comparable { public mutating func sort () { ... } }
延迟序列 LazySequenceProtocol 和 LazyCollectionProtocol。
延迟编程:结果只有在真正需要的时候才会计算出来。
swift 标准库为支持延迟编程,提供了两个协议:LazySequenceProtocol 和 LazyCollectionProtocol。
LazySequenceProtocol 继承自 Sequence。
LazyCollectionProtocol 继承自 LazySequenceProtocol。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 let filtered = standardIn.filter { $0 .split(separator: " " ).count > 3 } for line in filtered { print (line) }for line in standardIn { guard line.split(separator: " " ).count > 3 else { continue } print (line) } let filtered = standardIn.lazy.filter { $0 .solit(separator: " " ).count > 3 } for line in filtered { print (line) }
风格比较
1 2 3 4 5 6 7 8 9 10 11 12 let result = Array (standardIn.lazy.filter { $0 .split(separator: " " ).count > 3 }.prefix(2 )) var result: [String ] = []for line in standardIn { guard line.split(separator: " " ).count > 3 else { continue } result.append(line) if result.count == 2 { break } }
当在一个常规集合类型(Array)上,串联多个操作时,可以延迟处理的序列,会更效率。
1 (1 ..< 100 ).map { $0 * $0 }.filter {$0 > 10 }.map { "\($0 ) " }
函数式编程,代码清晰易于理解,但是存在效率不佳的问题:
每一次调用 map 和 filter,都会创建一个新的包含中间结果的数组,这个数组在返回的时候就被销毁了。
通过在这个调用链的开始,插入 .lazy,就不会产生任何保存中间结果的数组,更有效率
1 (1 ..< 100 ).lazy.map { $0 * $0 }.filter {$0 > 10 }.map { "\($0 ) " }
LazyCollectionProtocol 扩展了 LazySequence,它要求实现它的类型也是一个实现了 Collection 的类型。
在 LazySquence 中,我们只能逐个生成 Sequence 中的每个元素。
在 LazyCollection 中,我们可以直接按需生成指定的某个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 let allNumbers = 1 ..< 1_000_000 let allSquares = allNumbers.lazy.map { $0 * $0 }print (allSquares[50 ]) let largeSquares = allNumbers.lazy.filter { $0 > 1000 }.map { $0 * $0 }print (largeSquares[50 ])